Publications
2026
-
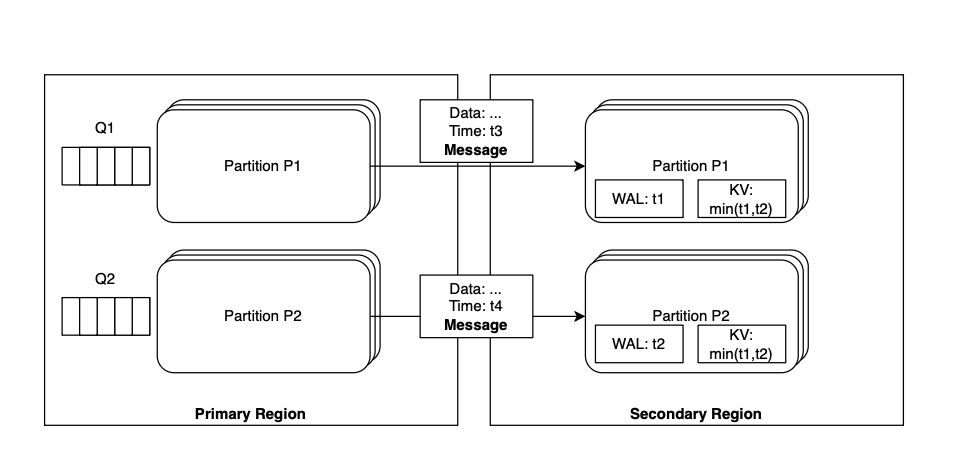 Rosé: Flexible Replication With Strong Semantics For Partitioned DatabasesIn CIDR 2026
Rosé: Flexible Replication With Strong Semantics For Partitioned DatabasesIn CIDR 2026Asynchronous primary-backup database replication is popular because it strikes a desirable balance between write latency and durability. Unfortunately, it has significant downsides. In partitioned databases, each partition is typically replicated independently, which means that data loss during failover can leave the database in an undefined state that is hard for developers to reason about. In addition, replication lag can grow over time, expose users to stale data and create durability issues. Finally, time to recovery and performance after failover can suffer if backup partitions progress unevenly. Rosé is a novel replication scheme to address the limitations of asynchronous primary backup replication in partitioned databases, by striking a balance between full synchronicity and asynchronicity. First, databases integrate existing their existing snapshotting mechanisms (e.g., real-time or epochs) with asynchronous replication to provide monotonic-prefix consistency semantics at the backup. Second, in order to bound replication lag, Rosé proposes push-based replication that can track the lag and apply backpressure at the primary, in a way that maintains high availability. Third, Rosé ensures fast recovery and full performance after failover by separating the replication of writes from their application to the backup partition’s key-value store. We integrate Rosé with Chablis, a geo-distributed, multi-versioned transactional key-value store to preserve the benefit of fast single datacenter (DC) transactions while ensuring multi-DC durability.
2025
-
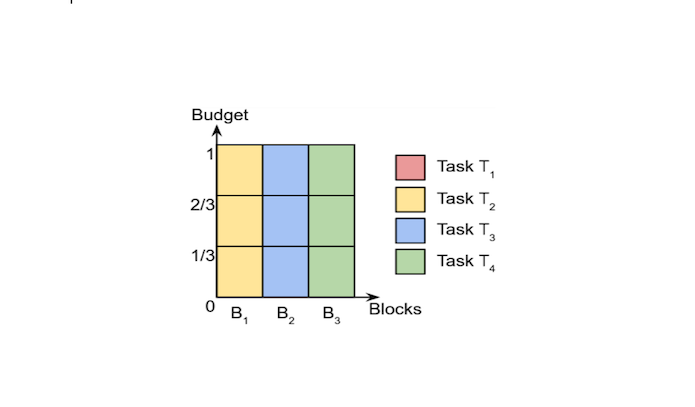 Efficiently Packing Privacy Budget with DPackPierre Tholoniat*, Kelly Kostopoulou*, Mosharaf Chowdhury, and 4 more authorsIn EuroSys 2025
Efficiently Packing Privacy Budget with DPackPierre Tholoniat*, Kelly Kostopoulou*, Mosharaf Chowdhury, and 4 more authorsIn EuroSys 2025Machine learning (ML) models can leak information about users, and differential privacy (DP) provides a rigorous way to bound that leakage under a given budget. This DP budget can be regarded as a new type of compute resource in workloads of multiple ML models training on user data. Once it is used, the DP budget is forever consumed. Therefore, it is crucial to allocate it most efficiently to train as many models as possible. This paper presents the scheduler for privacy that optimizes for efficiency. We formulate privacy scheduling as a new type of multidimensional knapsack problem, called privacy knapsack, which maximizes DP budget efficiency. We show that privacy knapsack is NP-hard, hence practical algorithms are necessarily approximate. We develop an approximation algorithm for privacy knapsack, DPK, and evaluate it on microbenchmarks and on a new, synthetic private-ML workload we developed from the Alibaba ML cluster trace. We show that DPK: (1) often approaches the efficiency-optimal schedule, (2) consistently schedules more tasks compared to a state-of-the-art privacy scheduling algorithm that focused on fairness (1.3-1.7x in Alibaba, 1.0-2.6x in microbenchmarks), but (3) sacrifices some level of fairness for efficiency. Therefore, using DPK, DP ML operators should be able to train more models on the same amount of user data while offering the same privacy guarantee to their users.
-

2024
-
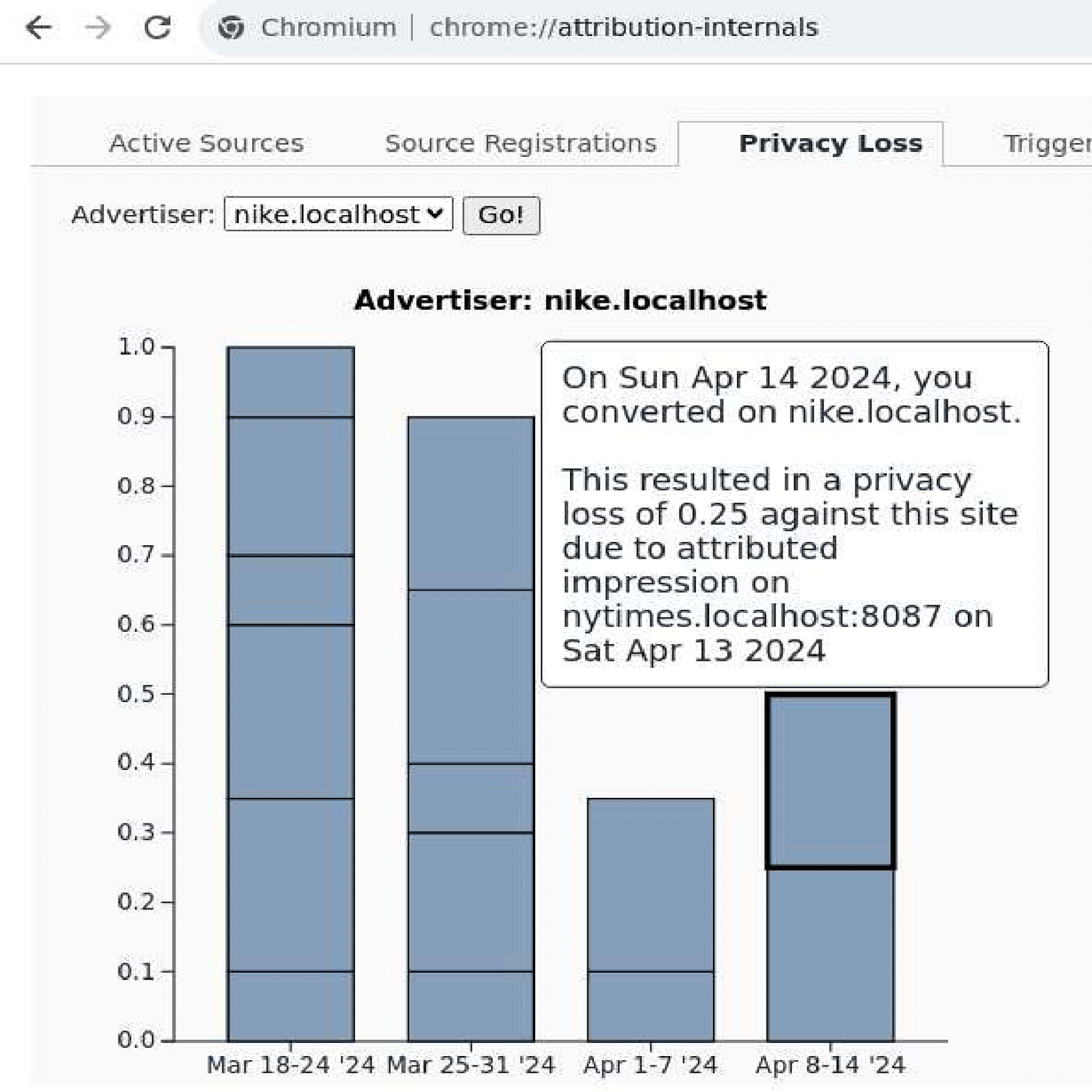 Cookie Monster: Efficient On-device Budgeting for Differentially-Private Ad-Measurement SystemsPierre Tholoniat*, Kelly Kostopoulou*, Peter McNeely, and 6 more authorsIn Proceedings of the 30th Symposium on Operating Systems Principles 2024
Cookie Monster: Efficient On-device Budgeting for Differentially-Private Ad-Measurement SystemsPierre Tholoniat*, Kelly Kostopoulou*, Peter McNeely, and 6 more authorsIn Proceedings of the 30th Symposium on Operating Systems Principles 2024With the impending removal of third-party cookies from major browsers and the introduction of new privacy-preserving advertising APIs, the research community has a timely opportunity to assist industry in qualitatively improving the Web’s privacy. This paper discusses our efforts, within a W3C community group, to enhance existing privacy-preserving advertising measurement APIs. We analyze designs from Google, Apple, Meta and Mozilla, and augment them with a more rigorous and efficient differential privacy (DP) budgeting component. Our approach, called Alistair, enforces well-defined DP guarantees and enables advertisers to conduct more private measurement queries accurately. By framing the privacy guarantee in terms of an individual form of DP, we can make DP budgeting more efficient than in current systems that use a traditional DP definition. We incorporate Alistair into Chrome and evaluate it on microbenchmarks and advertising datasets. Across all workloads, Alistair significantly outperforms baselines in enabling more advertising measurements under comparable DP protection.
-
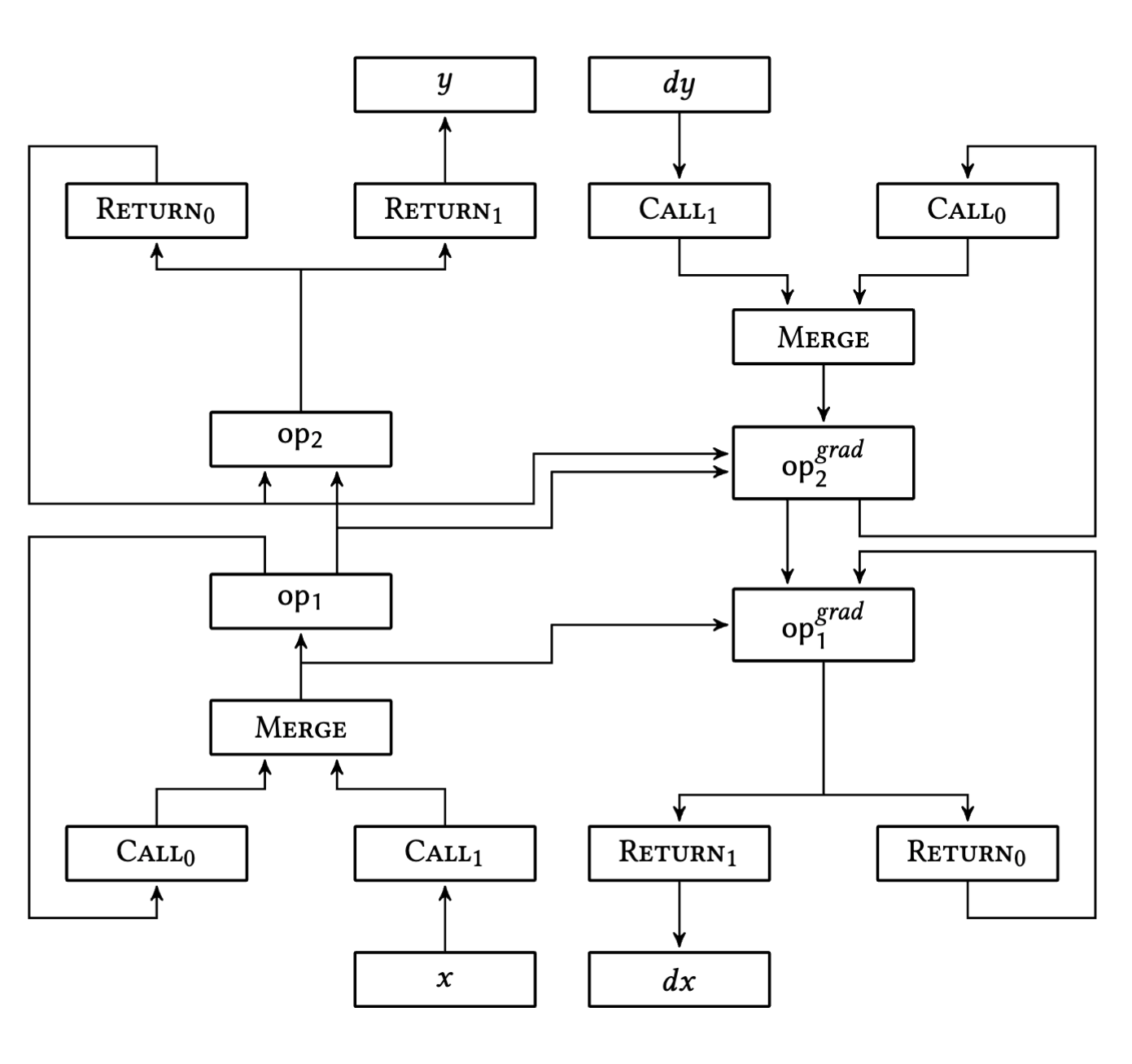 Recursive Function Definitions in Static Dataflow Graphs and their Implementation in TensorFlowKelly Kostopoulou, Angelos Charalambidis, and Panos Rondogiannis2024
Recursive Function Definitions in Static Dataflow Graphs and their Implementation in TensorFlowKelly Kostopoulou, Angelos Charalambidis, and Panos Rondogiannis2024Modern machine learning systems represent their computations as dataflow graphs. The increasingly complex neural network architectures crave for more powerful yet efficient programming abstractions. In this paper we propose an efficient technique for supporting recursive function definitions in dataflow-based systems such as TensorFlow. The proposed approach transforms the given recursive definitions into a static dataflow graph that is enriched with two simple yet powerful dataflow operations. Since static graphs do not change during execution, they can be easily partitioned and executed efficiently in distributed and heterogeneous environments. The proposed technique makes heavy use of the idea of tagging, which was one of the cornerstones of dataflow systems since their inception. We demonstrate that our technique is compatible with the idea of automatic differentiation, a notion that is crucial for dataflow systems that focus on deep learning applications. We describe the principles of an actual implementation of the technique in the TensorFlow framework, and present experimental results that demonstrate that the use of tagging is of paramount importance for developing efficient high-level abstractions for modern dataflow systems.
2023
-
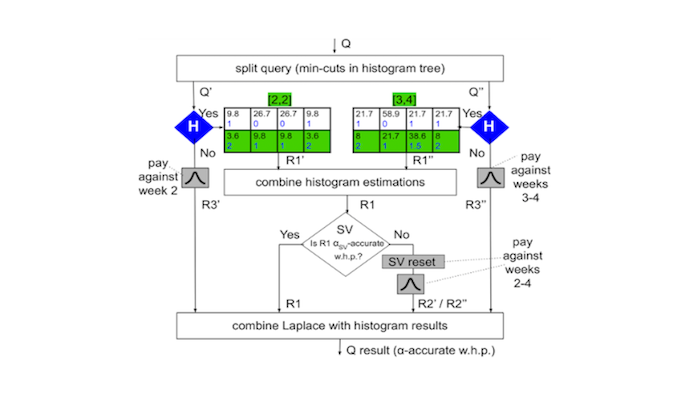 Turbo: Effective Caching in Differentially-Private DatabasesKelly Kostopoulou*, Pierre Tholoniat*, Asaf Cidon, and 2 more authorsIn Proceedings of the 29th Symposium on Operating Systems Principles 2023
Turbo: Effective Caching in Differentially-Private DatabasesKelly Kostopoulou*, Pierre Tholoniat*, Asaf Cidon, and 2 more authorsIn Proceedings of the 29th Symposium on Operating Systems Principles 2023Differentially-private (DP) databases allow for privacy-preserving analytics over sensitive datasets or data streams. In these systems, user privacy is a limited resource that must be conserved with each query. We propose Turbo, a novel, state-of-the-art caching layer for linear query workloads over DP databases. Turbo builds upon private multiplicative weights (PMW), a DP mechanism that is powerful in theory but ineffective in practice, and transforms it into a highly-effective caching mechanism, PMW-Bypass, that uses prior query results obtained through an external DP mechanism to train a PMW to answer arbitrary future linear queries accurately and "for free" from a privacy perspective. Our experiments on public Covid and CitiBike datasets show that Turbo with PMW-Bypass conserves 1.7 – 15.9\texttimes more budget compared to vanilla PMW and simpler cache designs, a significant improvement. Moreover, Turbo provides support for range query workloads, such as timeseries or streams, where opportunities exist to further conserve privacy budget through DP parallel composition and warm-starting of PMW state. Our work provides a theoretical foundation and general system design for effective caching in DP databases.
2021
-
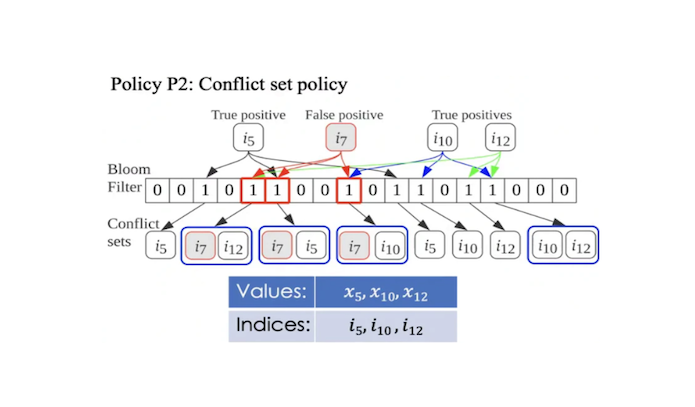 DeepReduce: A Sparse-tensor Communication Framework for Federated Deep LearningHang Xu, Kelly Kostopoulou, Aritra Dutta, and 3 more authorsIn Advances in Neural Information Processing Systems 2021
DeepReduce: A Sparse-tensor Communication Framework for Federated Deep LearningHang Xu, Kelly Kostopoulou, Aritra Dutta, and 3 more authorsIn Advances in Neural Information Processing Systems 2021Sparse tensors appear frequently in federated deep learning, either as a direct artifact of the deep neural network’s gradients, or, as a result of an explicit sparsification process. Existing communication primitives are agnostic to the challenges of deep learning; consequently, they impose unnecessary communication overhead. This paper introduces DeepReduce, a versatile framework for the compressed communication of sparse tensors, tailored to federated deep learning. DeepReduce decomposes sparse tensors into two sets, values and indices, and allows both independent and combined compression of these sets. We support a variety of standard compressors, such as Deflate for values, and Run-Length Encoding for indices. We also propose two novel compression schemes that achieve superior results: curve-fitting based for values, and bloom-filter based for indices. DeepReduce is orthogonal to existing gradient sparsifiers and can be applied in conjunction with them, transparently to the end-user, to significantly lower the communication overhead. As a proof of concept, we implement our approach on TensorFlow and PyTorch. Our experiments with real models demonstrate that DeepReduce transmits 320% less data than existing sparsifiers, without affecting accuracy.